ТИТАНИК. ПОСТРОЕНИЕ МОДЕЛИ. Часть 1.
=====================================
ФОРМИРОВАНИЕ ПРИЗНАКОВ (FEATURES)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
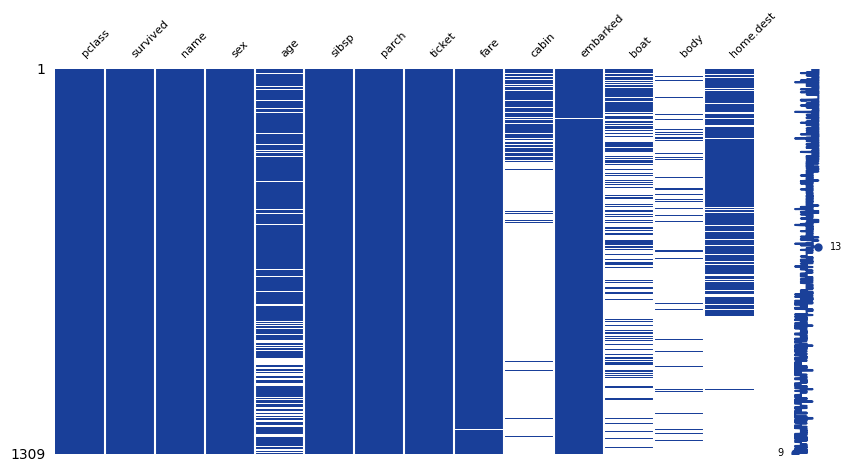
Знакомая картинка из предадущего ролика.
Здесь хорошо видны колонки, содержащие пустоты.
Фильтруем колонки
Исключить уникальные
id — идентификатор
name — ФИО пассажира
ticket — номер билета
home — адрес
Исключить содержащие много пустот
age — возраст
cabin — номер каюты
boat — номер лодки куда попал выживший
body — номер лодки куда было поднято тело погибшего
Включить остальные
pclass — класс купленного билета (1-й, 2-й, или 3-й)
sex — пол пассажира
sibsp — количество братьев или супругов у пассажира на борту
parch — количество родителей или детей у пассажира на борту
fare — сумма денег, которую заплатили за билет
embarked — порт (город), где пассажир сел на Титаник
Целевой признак
survived — выжил ли пассажир: да = 1, нет = 0
Возраст очень важный признак - нужно попытаться
заполнить пустоты и включить его в признаки.
С этого места начинается тяжелая работа по приведению данных
к состоянию пригодному для обучению модели. Осилят не все.
-- Продолжение работы в PostgreSQL --
В таблице tit1 поля age и fare текстовые т.к. в дробных
значениях запятая, а Postgres понимает только точку.
select id, age, fare from tit1 limit 7;
Исправить это: заменить , на .update tit1 set
age = replace(age, ',', '.'),
fare = replace(fare, ',', '.')
where age like '%,%' or fare like '%,%';
Создать таблицу tit2 с типом float (число с плавающей точкой)
для полей age и fare (возраст и цена билета)
create table tit2 (
id serial,
pclass int,
survived int,
name varchar,
sex varchar,
age float,
sibsp int,
parch int,
ticket varchar,
fare float,
cabin varchar,
embarked varchar,
boat varchar,
body varchar,
home varchar
);
create UNIQUE index on tit1 (id);
Перелить исправленные данные из tit1 в tit2
insert into tit2 (
id, pclass, survived, name, sex, age, sibsp,parch,
ticket, fare, cabin, embarked, boat, body, home
)
select
id, pclass, survived, name, sex, age::float, sibsp, parch,
ticket, fare::float, cabin, embarked, boat, body, home
from tit1;
НАЙТИ МЕДИАННЫЕ ЗНАЧЕНИЯ
------------------------
ДЛЯ FARE - ПО КЛАССУ КАЮТЫ
Найти пустые значения цены билета
select id, pclass, age, fare from tit2
where fare is null;
id | pclass | age | fare
------+--------+------+------
1226 | 3 | 60.5 | ¤
Оказалось только одно.
Вычислить медиану цены для 3-го класса
select percentile_cont (0.5) within
group (order by fare)
from tit2 where pclass = 3 and fare is not null;
percentile_cont
-----------------
8.05
Заменить NULL на вычисленное медианное значение цены
для 3-го класса
update tit2 set fare = 8.05 where id = 1226;
ДЛЯ AGE - ПО ТИТУЛУ
Выделить титулы такие как: Miss, Mr, Master,
пользуясь тем, что в начале их всегда есть ', '
а в конце '. '
select distinct
substring(name,
position(', ' in name) + 2,
position('. ' in name) -
position(', ' in name) - 2)
as titul
from tit2 order by titul;
titul
--------------
Capt
Col
Don
Dona
Dr
Jonkheer
Lady
Major
Master
Miss
Mlle
Mme
Mr
Mrs
Ms
Rev
Sir
the Countess
(18 строк)
Заменить NULL на вычисленное медианное значение возраста
для каждого титула в отдельности
Помог ИИ: https://www.phind.com/search/cmfyvgkkp00002v6t6pwbj2v7
НАЧАЛО ЗАПРОСА
``````````````
-- Получаем все возможные титулы
WITH titles AS (
select distinct
substring(name,
position(', ' in name) + 2,
position('. ' in name) -
position(', ' in name) - 2)
as titul
from tit2
),
-- Вычисляем медианы для каждого титула
medians AS (
SELECT
tit2.titul,
PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY t2.age)
AS median_age
FROM titles tit2
JOIN tit2 t2 ON
substring(t2.name,
position(', ' in t2.name) + 2,
position('. ' in t2.name) - position(', '
in t2.name) - 2) = tit2.titul
WHERE t2.age IS NOT NULL
GROUP BY tit2.titul
)
-- Обновляем NULL значения
UPDATE tit2
SET age = m.median_age
FROM medians m
WHERE tit2.age IS NULL
AND substring(tit2.name,
position(', ' in tit2.name) + 2,
position('. ' in tit2.name) - position(', '
in tit2.name) - 2) = m.titul;
ОКОНЧАНИЕ ЗАПРОСА
`````````````````
Окончательный список признаков (7 штук)
age — возраст пассажира
pclass — класс купленного билета (1-й, 2-й, или 3-й)
sex — пол пассажира
sibsp — количество братьев или супругов на борту
parch — количество родителей или детей на борту
fare — сумма денег, которую заплатили за билет
embarked — порт (город), где пассажир сел на Титаник
Поверить их полноту т.е. нет ли в каком-нибудь из признаков
пустых значений:
select * from tit2 where
age is null or
pclass is null or
sex is null or
sibsp is null or
parch is null or
fare is null or
embarked is null ;
-[ RECORD 1 ]---------------------------------------
id | 170
pclass | 1
survived | 1
name | Icard, Miss. Amelie
sex | female
age | 38
sibsp | 0
parch | 0
ticket | 113572
fare | 80
cabin | B28
embarked | ¤
boat | 6
body | ¤
home | ¤
-[ RECORD 2 ]---------------------------------------
id | 287
pclass | 1
survived | 1
name | Stone, Mrs. George Nelson (Martha Evelyn)
sex | female
age | 62
sibsp | 0
parch | 0
ticket | 113572
fare | 80
cabin | B28
embarked | ¤
boat | 6
body | ¤
home | Cincinatti, OH
Нашлось две записи с пустым портом посадки embarked
Починить embarked - порт в котором пассажир сел на Титаник
Для 1-го класса (ведь обе записи pclass = 1),
при цене близкой к 80 (fare = 80) и
без учета пустых значений (embarked is not null):
select embarked, count(*) from tit2 where
pclass = 1 and embarked is not null and
fare > 79 and fare < 81
group by embarked;
embarked | count
----------+-------
C | 6
S | 3
Принять embarked = 'C' и заполнить пустоты:
update tit2 set embarked = 'C' where id in (170, 287);
Поcледняя проверка на полноту
select * from tit2 where
age is null or
pclass is null or
sex is null or
sibsp is null or
parch is null or
fare is null or
embarked is null ;
0 строк - пустот нет.
Для тех кому все эти процедуры по восстановлению пропущенных
данных покажутся сложными и захочется просто отбросить строки
содержащие пустые значения (а это необходимо!) сравните:
select count(*) from tit2 where
age is not null and
pclass is not null and
sex is not null and
sibsp is not null and
parch is not null and
fare is not null and
embarked is not null ;
count
-------
1309
select count(*) from tit1 where
age is not null and
pclass is not null and
sex is not null and
sibsp is not null and
parch is not null and
fare is not null and
embarked is not null ;
count
-------
1043
Потеря данных, если отбросить пустоты ~20%, это не смертельно,
но качество модели в результате ухудшится, можно посчитать
насколько, но не сегодня.
bzip2-архивы дампа postgres-базы titanic можно скачать
здесь База в начале и база в конце ролика.
Начальный, для тех, кто честно проделает всю работу руками,
а конечный, для самых тупах и ленивых - там уже всё сделано,
если их скачать - распаковываются так:
bzip2 -d ИМЯ_ФАЙЛА.bz2
Конец